
搭建CEPH
搭建CEPH
什么是CEPH
主流存储应用有文件系统、块级别存储、对象存储三类主流应用
存储设备
DAS(Direct-Attached Storage):直接附加存储
- IDE,STAT,SCSI,SAS,USB
NAS(Network Attached Storage):网络附加存储
- NFS,SMB,CIFS
通常本身就是文件系统
我没不能对它再进行分区和格式化
SAN(Storage Area Networ):存储区域网络
- SCSI,FC SAN, iSCSI
协议分层使我们可以替换其中一层比如吧ISCSI替换成光纤或以太网。
商业玩家
- EMC,DELl,net APP,IBM,HP
横向扩展的存储系统,分布式存储
- HDFS、CEPH
HDSF
分布式存储系统必然有路由功能,能将我的请求路由到相应的服务上。
在分布式存储系统中必然要用元数据来执行路由。这是一个标准的POSIX文件系统所具有的属性。
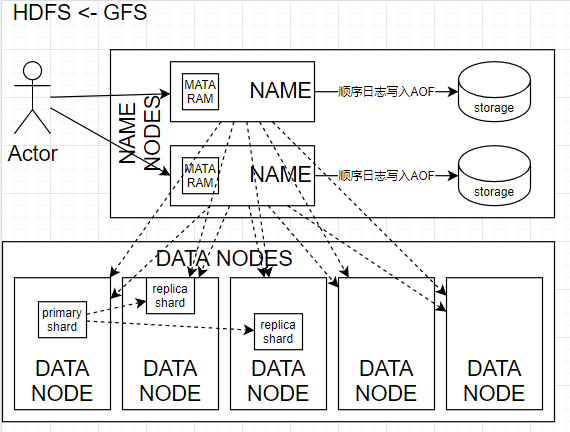
原理解释:
- DATANODE 文件碎片会以比如64MB一块的存储到节点的存储中
- NAMENODE 存储DATANODE的MATADATA信息。并且为访问做路由
- storage用zookeeper做存储
- primary shard 主分片
- replica shard 备份分片(主分片拷贝到备份分片)
- 位置信息 副本通常会被放在不同的机架上
- 通常只能顺序读写随机读但是不能随机写
ceph
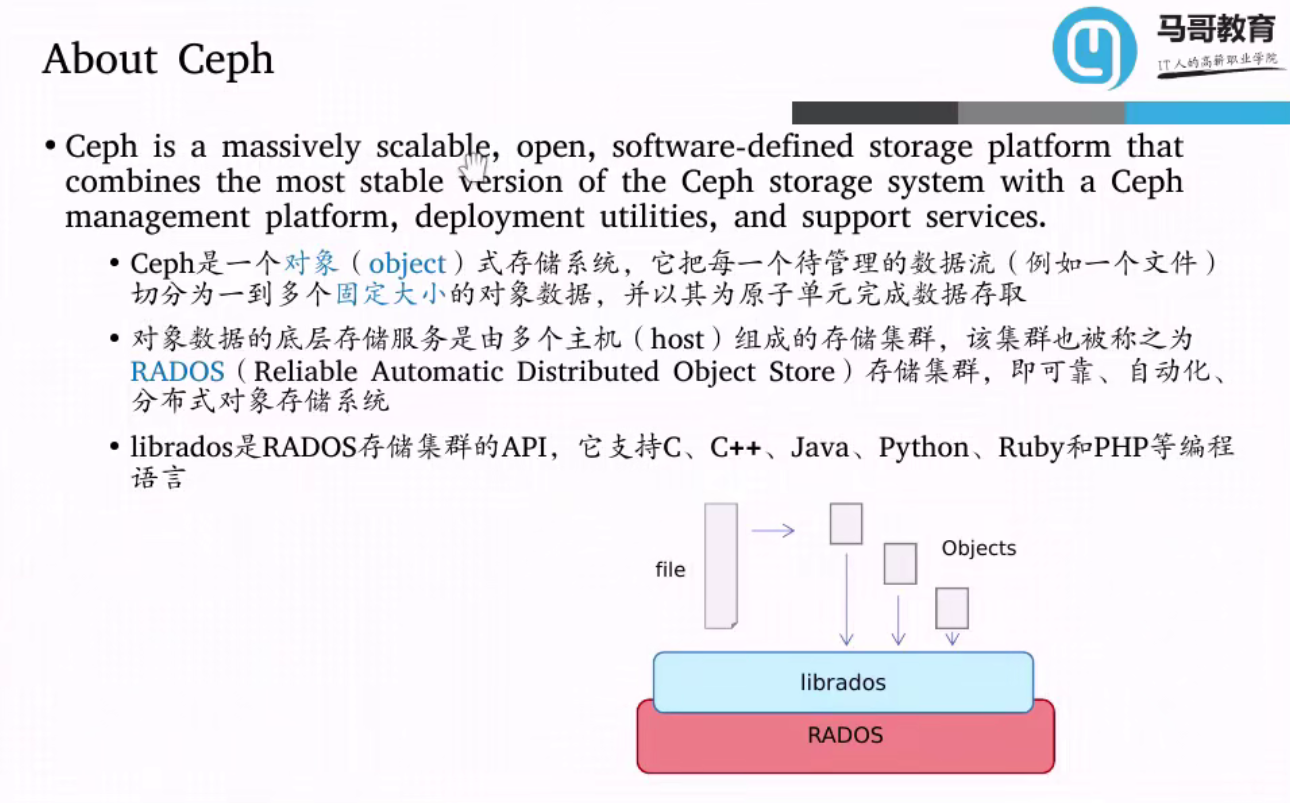
CEPH是一个对象存储系统
对象存储与文件存储的区别。
文件存储通常有一个称为“目录”的树形结构的索引与具体的文件。
而对象存储则是一个Key Value对的存储结构 Key是对象的ID而Value是对象的内容。
CEPH在设计上就是要解决类似于HDFS在读写存储时NameNode成为性能瓶颈的问题,比如通一致性hash计算逻辑可以找到相应的存储
CRUSH算法-在CEPH中提供一致性hash算法的方式
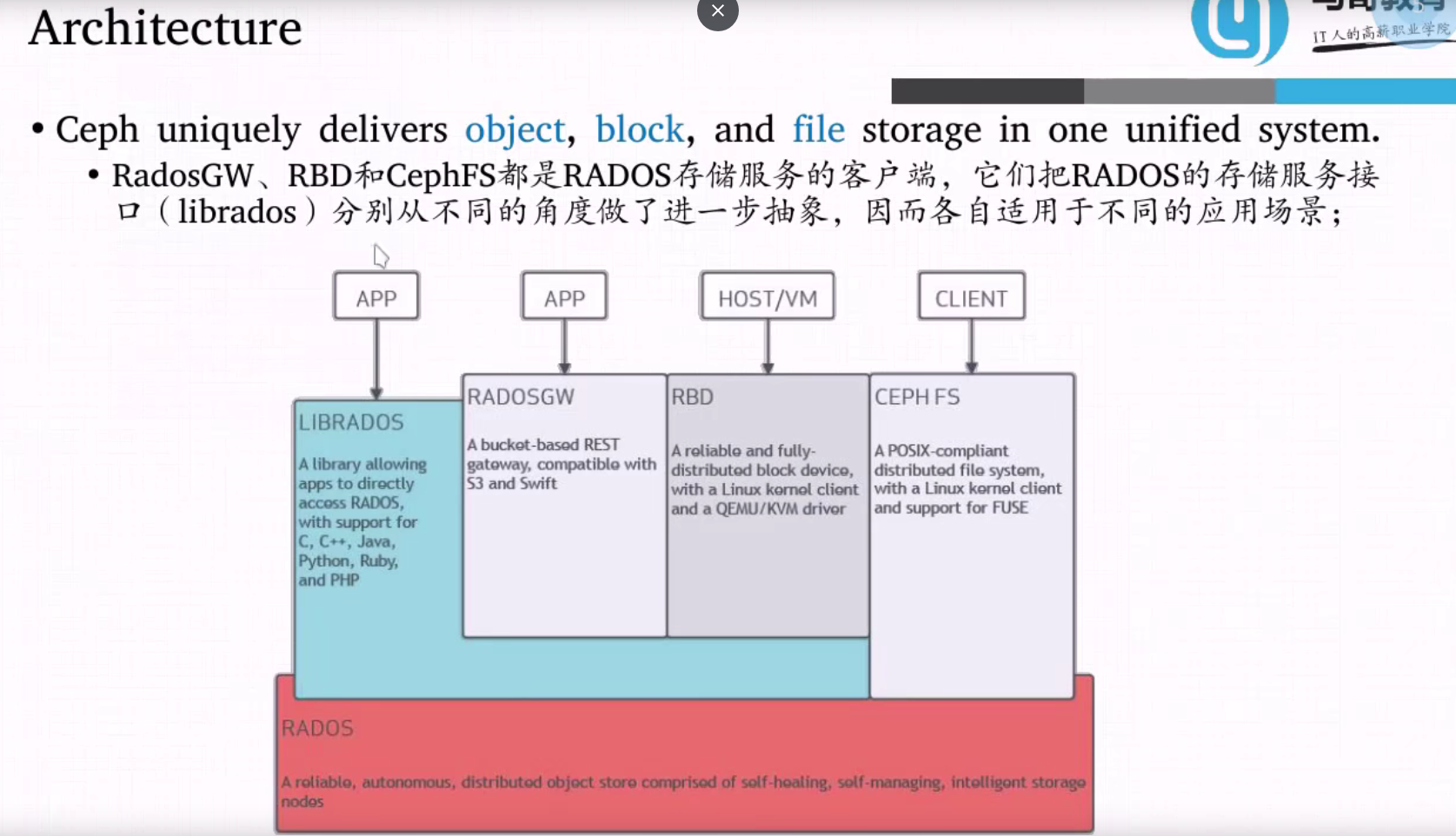
ceph 接口
CLIENT: CEPH FS
提供了类似文件系统的访问方式 与CFS很想
RBD 将CEPH提供的空间作为一个有一个的独立块来使用
RADOSGW 跨互联网使用的对象存储
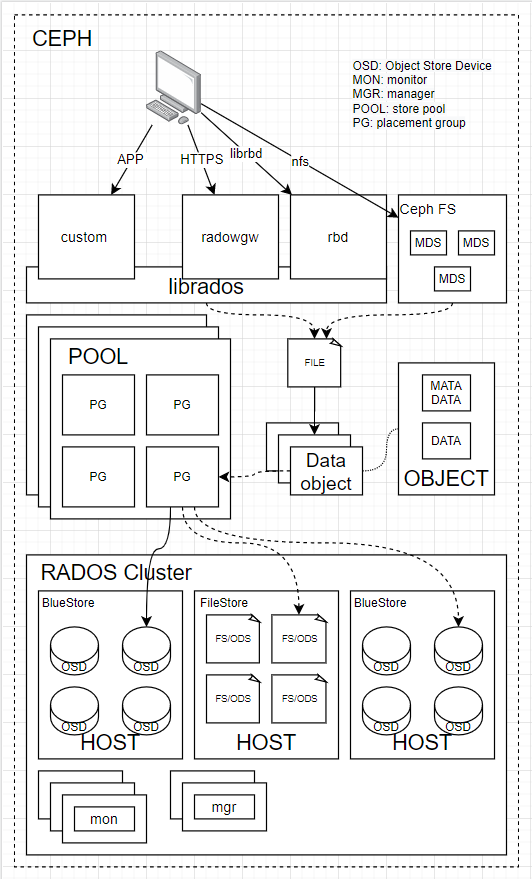
ceph 概念
关键组件OSDs Monitors Managers MDSs
RADOS Cluster
是ceph集群中最为核心的组件,他会吧文件切成多个对象。要被基于cluster算法实时计算后映射到集群中的某个osd中。
OSD(ceph-osd): Object Store Device
根据object所在PG、副本数量找到足量的OSD来存储。
每个磁盘会有一个ceph-osd进行管理。
对象存储守护进程
ceph-osd)存储数据,处理数据复制、恢复、重新平衡,并通过检查其他 Ceph OSD 守护进程的心跳来向 Ceph 监视器和管理器提供一些监控信息。通常至少需要 3 个 Ceph OSD 来实现冗余和高可用性。MON: monitor(ceph-mon)
monitor 是**cluster map(集群状运行图)**的持有者,并且负责维护并执行cephX 认证
Monitors:Ceph Monitor (
ceph-mon) 维护集群状态的映射,包括监视器映射、管理器映射、OSD 映射、MDS 映射和 CRUSH 映射。这些映射是 Ceph 守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。通常至少需要三个监视器才能实现冗余和高可用性。MGR: manager(ceph-mgr)
Ceph 管理器守护进程 (
ceph-mgr) 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。Ceph 管理器守护进程还托管基于 Python 的模块来管理和公开 Ceph 集群信息,包括基于 Web 的Ceph 仪表板和 REST API。高可用性通常至少需要两个管理器。POOL: store pool
当一个对象名字对64做一致性哈希映射并映射到一个哈希环上
PG: placement group
当一个对象进入pool后顺时针找到最近的一个PG并,存储到PG中
pg数量越多数据管理越精细,
mds: mata data service
兼容posix file system
radosgow CEPH Object Gateway
纠删码存储池: 一种冗余方式类似raid5
典型的ceph架构图
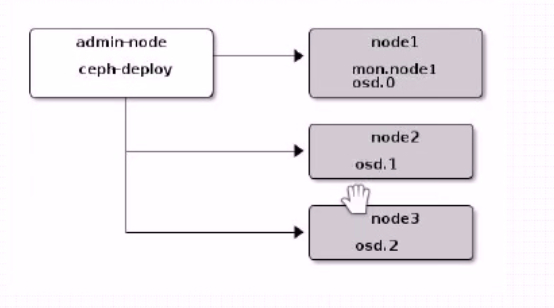
部署工具介绍

ceph-deploy 是ceph官方的部署工具
ceph-ansible 是红帽也就是ceph的东家推荐的工具。
由于我没学过ansible这里推荐使用ceph-deploy 来进行部署,ceph-deploy部署的过程只需要基于ssh sudo和一些python库就能够完成
部署
部署计划
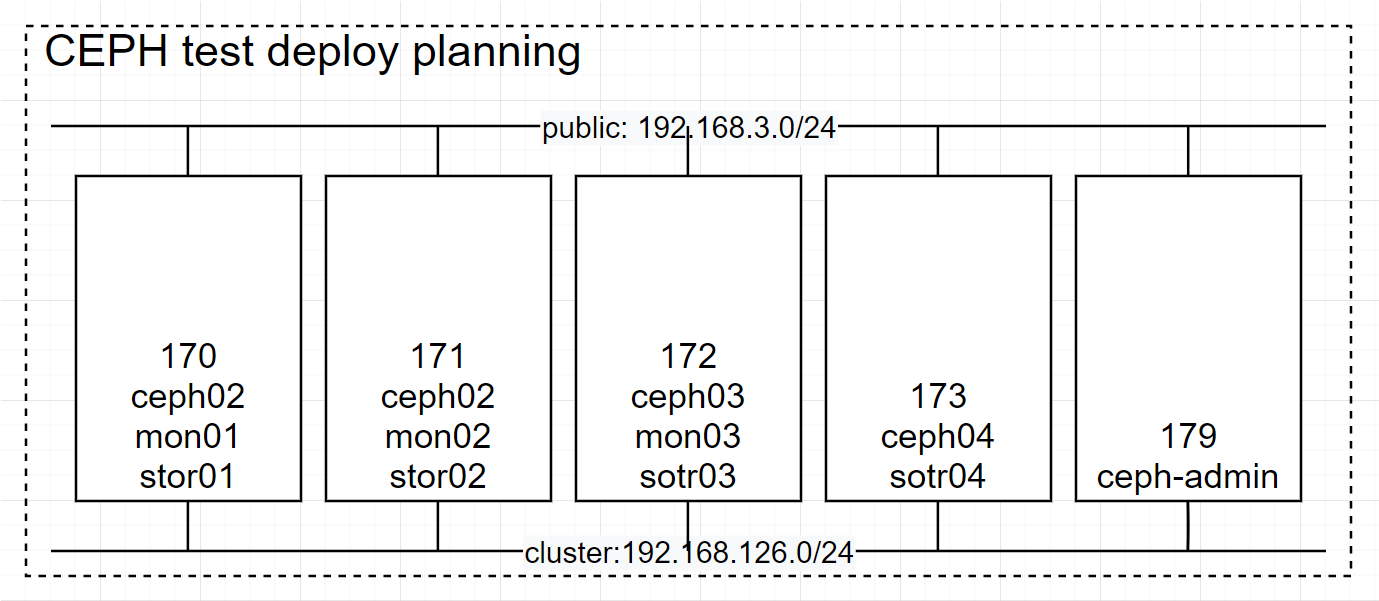
服务器准备
时钟同步
1 | systemctl start chronyd.service |
确保硬盘挂载
确保机器2、3、4上有4块硬盘机器1用于master
查看硬盘是否挂载成功
sda\sdb\sdc\sdd 四块硬盘
1 | fdisk -l /dev/sd* |
确保服务器有两块网
一块对外、一块对内 对外的叫public 对内的叫cluster
关闭防火墙
1 | systemctl stop firewalld |
解析主机名称
应该用DNS或hosts解析主机名称
- 外网DNS
- ceph0x.akachi
- ceph-admin.akachi
- 内网DNS
- ceph0x.cluster.akachi
- mon0x.cluster.akachi
- sotr0x.cluster.akachi
准备ceph文件
下载 安装程序包
访问:https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm
https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
较新的
这是一个生成yum仓库包的程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29rpm -ivh https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm
rpm -ivh https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
[root@ceph-admin yum.repos.d]# cat /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://download.ceph.com/rpm-mimic/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-mimic/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-mimic/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc安装epel-releas
1
2yum install epel-release -y
如果能够连接互联网那么epel会在未来安装ceph时自动解决依赖帮助我没安装。
创建用户新用户账号来实现维护
我们基于普通用户来完成部署和安装操作所以这里要创建用户(不要使用ceph)
1 | useradd cephadm |
确保cephadm能够在任何情况下使用sudo命令
1 | echo "cephadm ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadm |
测试
1 | sudo su cephadm |
相互免密登陆
创建密钥
只需要在一台服务器上进行
1
2ssh-keygen -t rsa -P ''
ssh-copy-id -i .ssh/id_rsa.pub cephadm@localhost创建
拷贝到所有服务器
1
scp -rp .ssh/ cephadm@ceph0x.akachi:/home/cephadm/
ssh用所有服务器登陆一边所有服务器的所有域名
1
ssh ceph-admin
在管理节点上安装ceph-deploy 程序包
1 | yum update |
部署RADOS存储集群
初始化RADOS集群
deploy 命令
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
[cephadm@ceph-admin ~]$ ceph-deploy -h
usage: ceph-deploy [-h] [-v | -q] [--version] [--username USERNAME]
[--overwrite-conf] [--ceph-conf CEPH_CONF]
COMMAND ...
Easy Ceph deployment
-^-
/ \
|O o| ceph-deploy v2.0.1
).-.(
'/|||\`
| '|` |
'|`
Full documentation can be found at: http://ceph.com/ceph-deploy/docs
optional arguments:
-h, --help show this help message and exit
-v, --verbose be more verbose
-q, --quiet be less verbose
--version the current installed version of ceph-deploy
--username USERNAME the username to connect to the remote host
--overwrite-conf overwrite an existing conf file on remote host (if
present)
--ceph-conf CEPH_CONF
use (or reuse) a given ceph.conf file
commands:
COMMAND description
new Start deploying a new cluster, and write a
CLUSTER.conf and keyring for it.
install Install Ceph packages on remote hosts.
rgw Ceph RGW daemon management
mgr Ceph MGR daemon management
mds Ceph MDS daemon management
mon Ceph MON Daemon management
gatherkeys Gather authentication keys for provisioning new nodes.
disk Manage disks on a remote host.
osd Prepare a data disk on remote host.
repo Repo definition management
admin Push configuration and client.admin key to a remote
host.
config Copy ceph.conf to/from remote host(s)
uninstall Remove Ceph packages from remote hosts.
purgedata Purge (delete, destroy, discard, shred) any Ceph data
from /var/lib/ceph
purge Remove Ceph packages from remote hosts and purge all
data.
forgetkeys Remove authentication keys from the local directory.
pkg Manage packages on remote hosts.
calamari Install and configure Calamari nodes. Assumes that a
repository with Calamari packages is already
configured. Refer to the docs for examples
(http://ceph.com/ceph-deploy/docs/conf.html)
See 'ceph-deploy <command> --help' for help on a specific command
new: 创建集群
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
usage: ceph-deploy new [-h] [--no-ssh-copykey] [--fsid FSID]
[--cluster-network CLUSTER_NETWORK]
[--public-network PUBLIC_NETWORK]
MON [MON ...]
Start deploying a new cluster, and write a CLUSTER.conf and keyring for it.
positional arguments:
MON initial monitor hostname, fqdn, or hostname:fqdn pair
optional arguments:
-h, --help show this help message and exit
--no-ssh-copykey do not attempt to copy SSH keys
--fsid FSID provide an alternate FSID for ceph.conf generation
--cluster-network CLUSTER_NETWORK
specify the (internal) cluster network
--public-network PUBLIC_NETWORKinstall: 安装ceph需要的软件包但是不启动
mon: 启动一个mon
在管理节点上以cephadm用户创建集群相关目录:
1
2mkdir ceph-cluster
cd ceph-cluster初始化第一个MON节点,准备创建集群:
指定内部网络 cluster-network
指定外部网络 public-network
mon要在外部网络而stor可以在内部
!!!默认的DNS可以无视后缀请求!!
1
ceph-deploy new --public-network 192.168.3.0/24 --cluster-network 192.168.126.0/24 ceph01 ceph02 ceph03
如果成功会生成三个文件
1
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
编辑生成的ceph.conf配置文件,在[global]配置段中设置ceph集群面向客户端通信时使用的IP地址所在网络,既公网网络地址:
检查ceph.conf文件如果有问题可以再更新文件内容
修改: 这里系统会错误指定host和mon name
mon_host = 192.168.3.170
1
2
3
4
5
6
7
8
9[global]
fsid = c6358ec6-6ecd-4546-ac3d-2ca82f9d2385
public_network = 192.168.3.0/24
cluster_network = 192.168.126.0/24
mon_initial_members = mon01.ceph.cluster.akachi
mon_host = 192.168.3.170
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx安装程序包
指定在哪些节点上安装程序包
1
2ceph-deploy install --cli ceph-admin
ceph-deploy install ceph01 ceph02 ceph03 ceph04等待完成
如果已经安装过包
1
ceph-deploy install --no-adjust-repos ceph01 ceph02 ceph03 ceph04
配置初始mon节点并收集所有密钥
初始化命令一定要在此前设定的工作目录下进行,也就是 ceph-cluster
1
ceph-deploy mon create-initial
报错:
这里需要使用短格式的名字长格式会失败
这里很容易出现错误请认真解决对比名称是否统一
- admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
1
由于命名不规范,new install 中出现的集群名字必须相同
如果修改了conf文件注意要
1
ceph-deploy --overwrite-conf config push ceph01.akachi ceph02.akachi ceph03.akachi ceph04.akachi
如果成功会在文件夹下创建一系列认证文件
1
2[cephadm@ceph-admin ceph-cluster]$ ls
ceph.bootstrap-mds.keyring ceph.bootstrap-mgr.keyring ceph.bootstrap-osd.keyring ceph.bootstrap-rgw.keyring ceph.client.admin.keyring ceph.conf ceph-deploy-ceph.log ceph.mon.keyringceph.client.admin.keyring是由所有权限的key
把配置文件和admin密钥拷贝到所有节
每次 ceph.conf发生变化都执行下列命令
1
ceph-deploy admin ceph01 ceph02 ceph03 ceph04 ceph-admin
设定普通用户可以访问admin密钥
1
sudo setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
创建一个mgr
1
ceph-deploy mgr create ceph01 ceph02
插卡式是否启动起来了
1
ps aux
确认集群是否监控
在admin 节点上安装ceph-common包
1
sudo yum install ceph-common -y
或者在ceph-admin上安装cli
1
ceph-deploy install --cli ceph-admin
查看是否健康
1
ceph -s
这里会报错由于我们没有权限,所以需要执行两行命令
1
2
3ceph-deploy admin ceph-admin.akachi
在所有服务器上执行
sudo setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
向RADOS集群添加OSD
列出并擦净磁盘
ceph-deploy disk 命令可以检查并列出OSD节点上所有可用磁盘的相关信息:
1 | [cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk list ceph01 ceph02 ceph03 ceph04 |
在管理节点上通过 disk zap 命令差出分区表和数据以便用于OSD,注意此设备会清除设备上的所有数据。
1 | ceph-deploy disk zap ceph01 /dev/sdb /dev/sdc /dev/sdd |
添加OSD
创建OSD命令
1 | [cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd --help |
创建命令
1 | ceph-deploy osd create --data /dev/sdb ceph01 |
停用OSD方法
OSD 由两个维度的状态
分别是out/in down/up
我们应该线out OSD然后 DOWN
- 停用设备:ceph OSD out {osd-num}
- 停止进程:sudo systemctl stop ceph-osd@{osd-num}
- 移除设备:ceph osd purge {id} –yes-i-really-mean-it
测试上传和下载数据对象
创建一个pool并指定其PG数量
1 | ceph osd pool create mypool 256 256 |
PG 也就是上面的64需要根据集群规模进行计算
查看是否创建成功
1 | ceph osd pool ls |
测试文件命令
1 | 上传文件 |
查看文件在哪
1 | ceph osd map mypool issue |
返回值解释
pool [poolname] 1 个对象 test01 放在 pg 1.1xxxxx中-> 文件存储在 up着的osd 1,11,6中 活动集 1 11 6 pg是p1
删除对象
1 | rados rm test01 -p mypool |
删除存储池
1 | ceph osd pool rm mypool mypool --yes-i-really-really-mean-it |
就算如此还是不让删除,你需要在配置文件中去加入允许删除的选项
扩容mon与mrg
扩容mon
mon 数量必须是奇数因为它使用怕克索斯协议。
1 | ceph-deploy mon add ceph02 |
这里和初始化一样需要使用短格式的名字
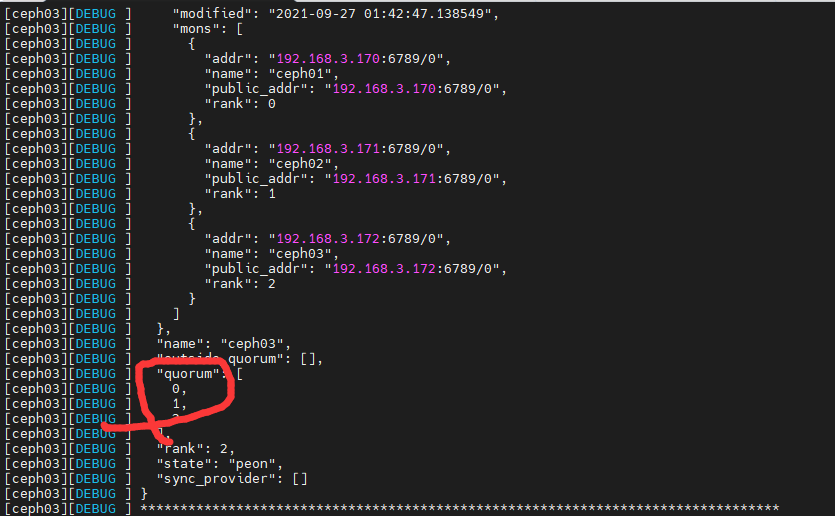
使用命令来查看节点状态
1 | ceph quorum_status --format json-pretty |
扩容mgr
1 | ceph-deploy mgr create ceph03 |
使用ceph s查看运行状态
块设备入门
安装客户端
在管理节点上,通过
ceph-deploy把 Ceph 安装到ceph-client节点。1
2
3ceph-deploy install ceph-client
# 实际语句
ceph-deploy install --cli ceph-admin在管理节点上,用
ceph-deploy把 Ceph 配置文件和ceph.client.admin.keyring拷贝到ceph-client。1
2
3ceph-deploy admin ceph-client
实际语句
ceph-deploy admin ceph-admin赋权
1
sudo setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
创建设备
使用块存储
在 ceph-client 节点上操作。
创建块设备映像
{pool-name}/{image-name}
存储池相关操作,可以参考 存储池
1 | ceph osd pool create mypool 128 |
映射块设备
{pool-name}/{image-name}
1 | sudo rbd map mypool/myimage --id admin |
事实上,创建的块设备映像,就在 /dev/rbd/{pool-name}/ 下:
1 | cd /dev/rbd/mypool |
使用块设备
/dev/rbd/{pool-name}/{image-name} 创建文件系统
1 | sudo mkfs.xfs /dev/rbd/mypool/myimage |
此命令可能耗时较长。
挂载文件
- 将该文件系统挂载到
/mnt/ceph-block-device文件夹下
1 | sudo mkdir /mnt/ceph-block-device |
此时,就可以使用 /mnt/ceph-block-device 这个目录了。
扩容设备
- 块设备扩容
1 | //调整块设备大小为20G |
解除挂载
解挂文件系统
1 | sudo umount /mnt/ceph-block-device |
如果解挂提示”device is busy”,则先执行:
1 | sudo yum install psmisc |
取消块设备映射
1 | sudo rbd unmap /dev/rbd/mypool/myimage |
删除块设备
1 | rbd rm mypool/myimage |
Cephfs使用方法
- Cephfs kernel module
- Cephfs-fuse
从上面的架构可以看出,Cephfs-fuse的IO path比较长,性能会比Cephfs kernel module的方式差一些;
Client端访问Cephfs的流程
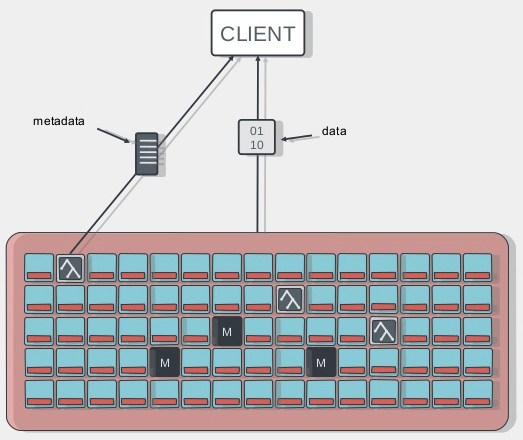
Cephfs cilent access
- client端与mds节点通讯,获取metadata信息(metadata也存在osd上)
- client直接写数据到osd
mds部署
使用ceph-deploy部署ceph mds很方便,只需要简单的一条命令就搞定,不过它依赖之前ceph-deploy时候生成的一些配置和keyring文件;
在之前部署ceph集群的节点目录,执行ceph-deploy mds create:
1 | 创建mds vi |
cephfs介绍
Ceph FS是一个支持POSIX接口的文件系统,它使用 Ceph 存储集群来存储数据。文件系统对于客户端来说可以方便的挂载到本地使用。Ceph FS构建在RADOS之上,继承RADOS的容错性和扩展性,支持冗余副本和数据高可靠性。
注意:当前, CephFS 还缺乏健壮得像 ‘fsck’ 这样的检查和修复功能。存储重要数据时需小心使用,因为灾难恢复工具还没开发完。
准备MDS元数据服务器
Ceph 文件系统要求 Ceph 存储集群内至少有一个 Ceph 元数据服务器。
新增一个MDS很简单,可参考ceph新增节点。
创建Ceph文件系统
一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。配置这些存储池时需考虑:
1、为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
2、为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。关于存储池的管理可参考官网 存储池。
要用默认设置为文件系统创建两个存储池,你可以用下列命令:
比如我们使用120个pg。cephfs_data和cephfs_metadata是两个存储池的名称。
1 | ceph osd pool create cephfs_data 128 |
创建好存储池后,你就可以用 fs new 命令创建文件系统了:
1 | ceph fs new cephfs cephfs_metadata cephfs_data |
cephfs是文件系统的名称。
使用下面的命令可以查看创建的CephFS
1 | ceph fs ls |
文件系统创建完毕后, MDS 服务器就能达到 active 状态了,比如在一个单 MDS 系统中,使用命令查看
1 | ceph mds stat |
成功运行输出如下:
1 | [zzq@ceph4 osd]$ ceph osd pool create cephfs_data 128 |
挂载CephFS (客户端节点执行)
要挂载 Ceph 文件系统,如果你知道监视器 IP 地址可以用 mount 命令、或者用 mount.ceph 工具来自动解析监视器 IP 地址。
假如我们有4个monitor监视器,ip分别为192.168.199.81,192.168.199.82,192.168.199.83,192.168.199.84。
则使用mount命令挂载到目录/mycephfs,如下:
1 | sudo mkdir /mycephfs |
正确输出如下:
1 | [zzq@localhost /]$ cat /etc/ceph/ceph.client.admin.keyring |
要卸载 Ceph 文件系统,可以用 umount 命令,例如:
1 | sudo umount /mycephfs |
可能遇到的问题
可能出现的错误
mount error 5 = Input/output error
mount error 22 = Invalid argument
第一个,首先先查mds服务是正常,不存在则添加
第二个,密钥不正确,检查密钥mount error 5
很可能是没有创建mds matedata server
用户空间挂载 CEPH 文件系统 (客户端服务器执行)
Ceph v0.55 及后续版本默认开启了 cephx 认证。
从用户空间挂载Ceph 文件系统前,确保客户端主机有一份Ceph 配置副本、和具备 Ceph元数据服务器能力的密钥环。
在客户端主机上,把监视器主机上的Ceph 配置文件拷贝到客户端服务器的 /etc/ceph/目录下。
1 | sudo mkdir -p /etc/ceph |
确保客户端机器上的 Ceph 配置文件和密钥环都有合适的权限位,如chmod 644 。
要把 Ceph 文件系统挂载为用户空间文件系统,可以用 ceph-fuse 命令,例如:
1 | sudo mkdir /data/ceph-nc |
启动时自动挂载
普通目录
输入以下内容:
每次启动重新挂载
1 | chmod u+x /etc/rc.d/rc.local |
用户目录
要在用户空间挂载 Ceph 文件系统,按如下加入 /etc/fstab :
1 | id=myuser,conf=/etc/ceph/ceph.conf /mnt/ceph2 fuse.ceph defaults 0 0 |
启动dashboard
mimic版 (nautilus版) dashboard 安装
如果是 (nautilus版) 需要安装 ceph-mgr-dashboard
yum install -y ceph-mgr-dashboard
添加mgr 功能
1
ceph-deploy mgr create ceph01 ceph02 ceph03 ceph04
开启dashboard 功能
1
ceph mgr module enable dashboard
创建证书
1
ceph dashboard create-self-signed-cert
创建 web 登录用户密码
1
ceph dashboard set-login-credentials user-name password
查看服务访问方式
1
ceph mgr services
OSD挂掉如何重启
查看所有OSD
1
ceph osd tree
资源
中文: http://docs.ceph.org.cn/install/install-ceph-deploy/
参考博客: https://www.cnblogs.com/zengzhihua/p/9829472.html#1-%E6%B7%BB%E5%8A%A0osd
视频教程: https://www.bilibili.com/video/BV17p4y1a7Em?p=5&spm_id_from=pageDriver